



仅作为记录经验的笔记
嘿嘿嘿
一、用到的神奇妙妙工具
- 用到的ai模型
- stable-diffusion (绘画)
- k-diffusion
- BLIP (视觉语言预训练 (VLP) 框架 、CLIP 优化版)
- gfpgan (脸部修复)
- CodeFormer (脸部修复)
*注意目录不能有中文,建议放在英文目录下
*注意CUDA的版本
二、步骤
用pip安装 pytorch 和cuda
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113检查cuda和pytorch是否可用
python -c "import torch; print(torch.cuda.is_available())"现在开始下载Stable-Diffusion-Webui框架和SD绘画各个步骤用到的模型框架
在作者项目页直接克隆https://github.com/AUTOMATIC1111/stable-diffusion-webui
或者用git命令克隆(D:/download 路径自己填写)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git D:/download下载完毕后进入stable-diffusion-webui文件夹,在文件夹内右键->Git Bash Here
下载 StableDiffusion(绘图) 和 CodeFormr(脸部修复)
git clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusion
git clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformers
git clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormer
git clone https://github.com/salesforce/BLIP.git repositories/BLIP下载安装Stable Diffusion的依赖
pip install transformers==4.19.2 diffusers invisible-watermark --prefer-binary下载安装k-diffusion
pip install git+https://github.com/crowsonkb/k-diffusion.git --prefer-binary下载gfpgan(可选) 负责脸部修复face restoration
pip install gfpgan安装之前下载的CodeFormer的依赖
pip install -r repositories/CodeFormer/requirements.txt --prefer-binary安装 web ui框架的依赖
pip install -r requirements.txt --prefer-binary更新numpy到最新版本(因为之前很多包都会引用到numpy所以为了保证版本统一,在此更新为最新版)
pip install -U numpy --prefer-binary下载模型 https://rentry.org/sdmodels
位置一律放在/stable-diffusion-webui/models/Stable-diffusion/ 下
三、训练模型
首先要做的是把stable-diffusion-webui/models/Stable-diffusion/里面的.vae文件重命名(别改完把原名给忘了,后面要再改回来)
用ps把需要训练的图片裁剪为正方形图片,放到一个文件夹里
到webui页面,选择顶部的settings选项卡
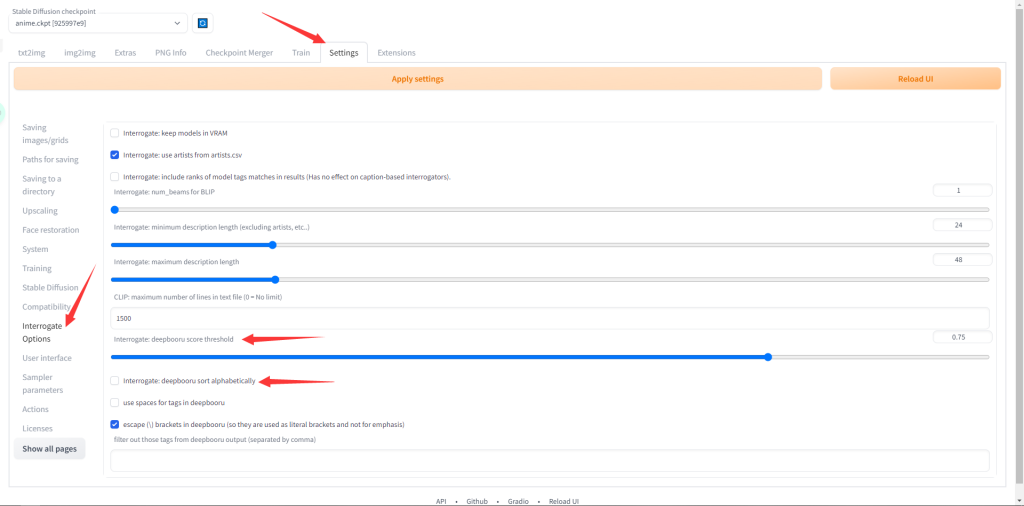
Interrogate: deepbooru score threshold 识别图片自动打标签的阈值,保持0.75就好,越高就越严格
Interrogate: deepbooru sort alphabetically 是否按字母排序预测结果,建议别勾选
设置好记得点顶上的Apply settings
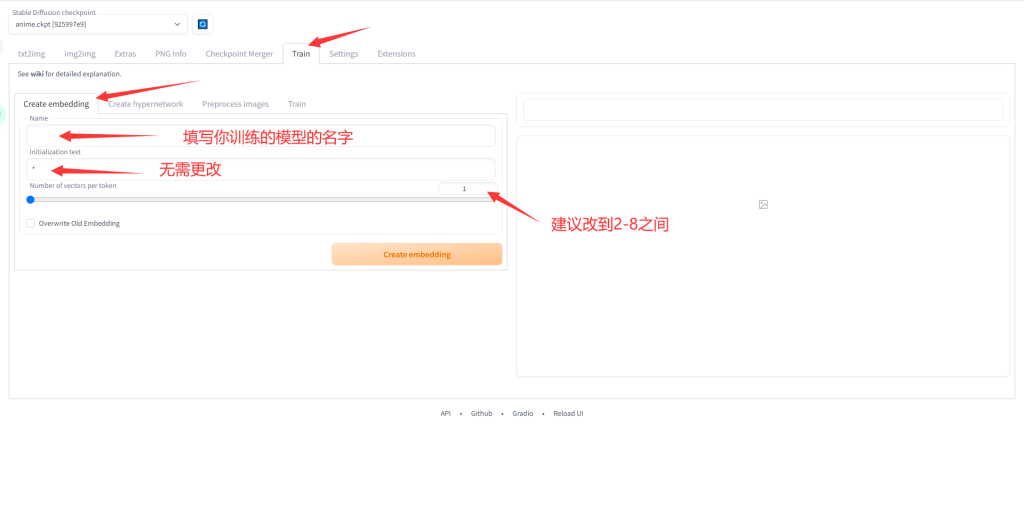
*注意:第二行initialization text可以用1girl,1boy这种描述总体性质的单个prompt,一般情况下无需更改
Number of vectors per token 表示的是你的embedding模型占用prompt数量,越高越好,但会占据写其他prompt的空间。设置好后点击Create embedding,会在你的stable-diffusion-webui文件夹根目录的embeddings文件下生成一个.pt文件。
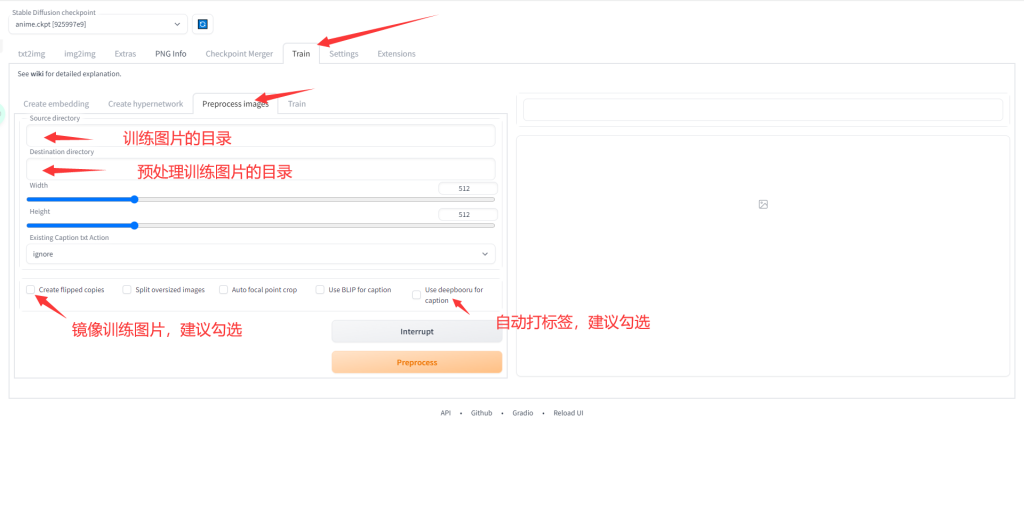
图片大小512就行,不是越大越好
设置完成后点击preprocess等待预处理完成。
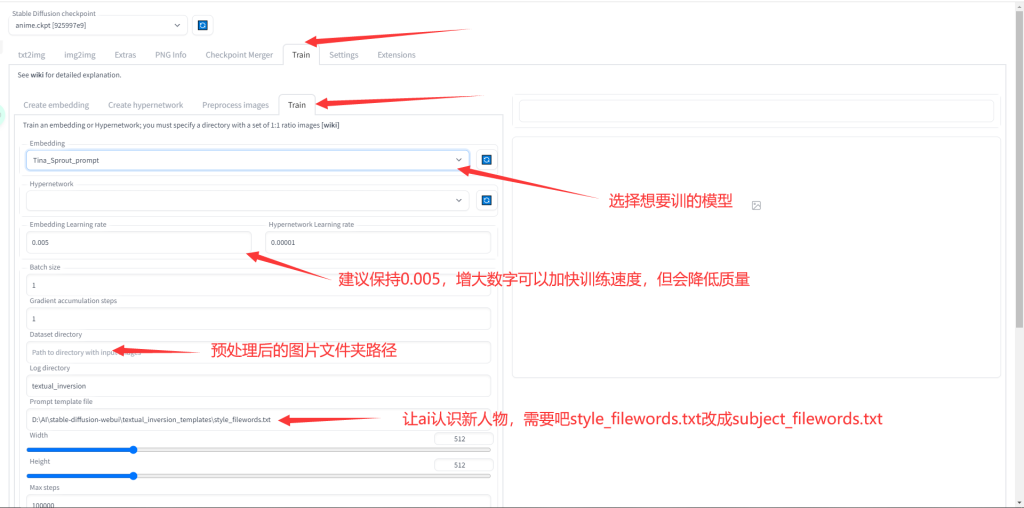
*注意:style_filewords.txt可以让ai学习新画风,subject_filewords.txt可以让ai学习某人某物
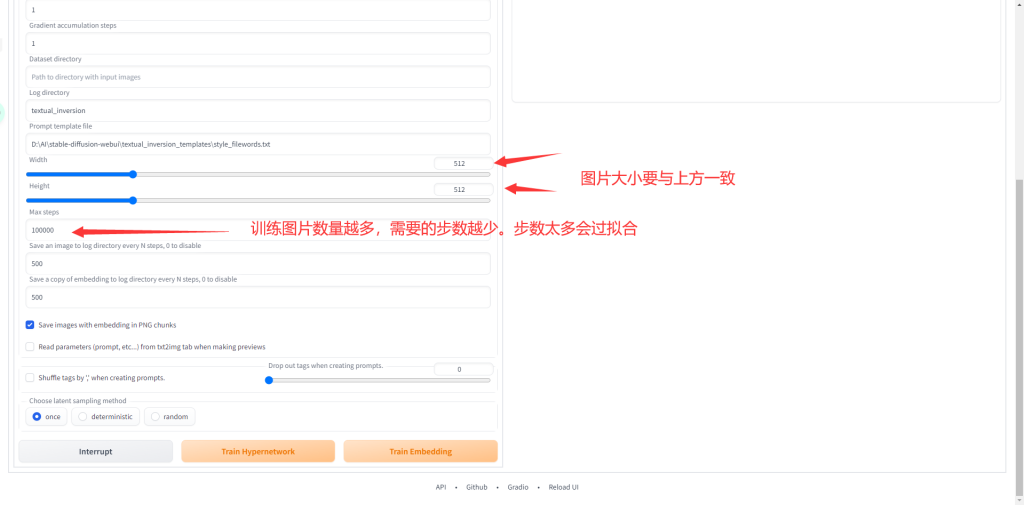
设置完成后可以点击Train Embedding开始训练,之后可以在控制台里看到训练进度和预估时间。
训练完成后把之前重命名的.vae文件名恢复。重启webui
之后生成人物可以在正面tag里加你已经训练好的模型的名字
四、后话
小提示1:gitclone.com:github.com镜像加速网站。在常规的git clone命令中嵌入gitclone.com可以提高clone速度和成功率。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
#这是原本的代码
git clone https://gitclone.com/github.com/AUTOMATIC1111/stable-diffusion-webui
#修改为这样小提示2:中间可能出现Visual C++ 14.0之类的问题,可以使用Microsoft Visual C++ Build Tools或者运行库合集之类的解决。
小提示3:手动安装pytorch https://pytorch.org/get-started/locally/
手动安装CUDA https://developer.nvidia.com/cuda-toolkit-archive
最后献上生成的图,包含我偷来的




Comments | NOTHING